epub 是什么
epub 是一种主流书本阅读格式,很多排版好的书本格式都是 epub。
epub 是一个压缩包,是类 html 文件、css 文件、配置文件以及字体图片等文件的集合。
为什么使用多看的 Dobby
有很多软件可以制作 epub 电子书,比如常见的 sigil。dobby 是基于 sigil 开发的,预先设置了一些样式,比如可以制作多看特有的弹注、全屏封面以及一些文字样式与区域样式。
优点是操作简单,可以比较容易排版出一个比较精美的电子书,不涉及 html 代码的操作。
缺点是不能操作源代码,无法自定义样式,要实现使用这些功能,需要使用其它软件,如 sigil。
简单来说,就是简单。
准备
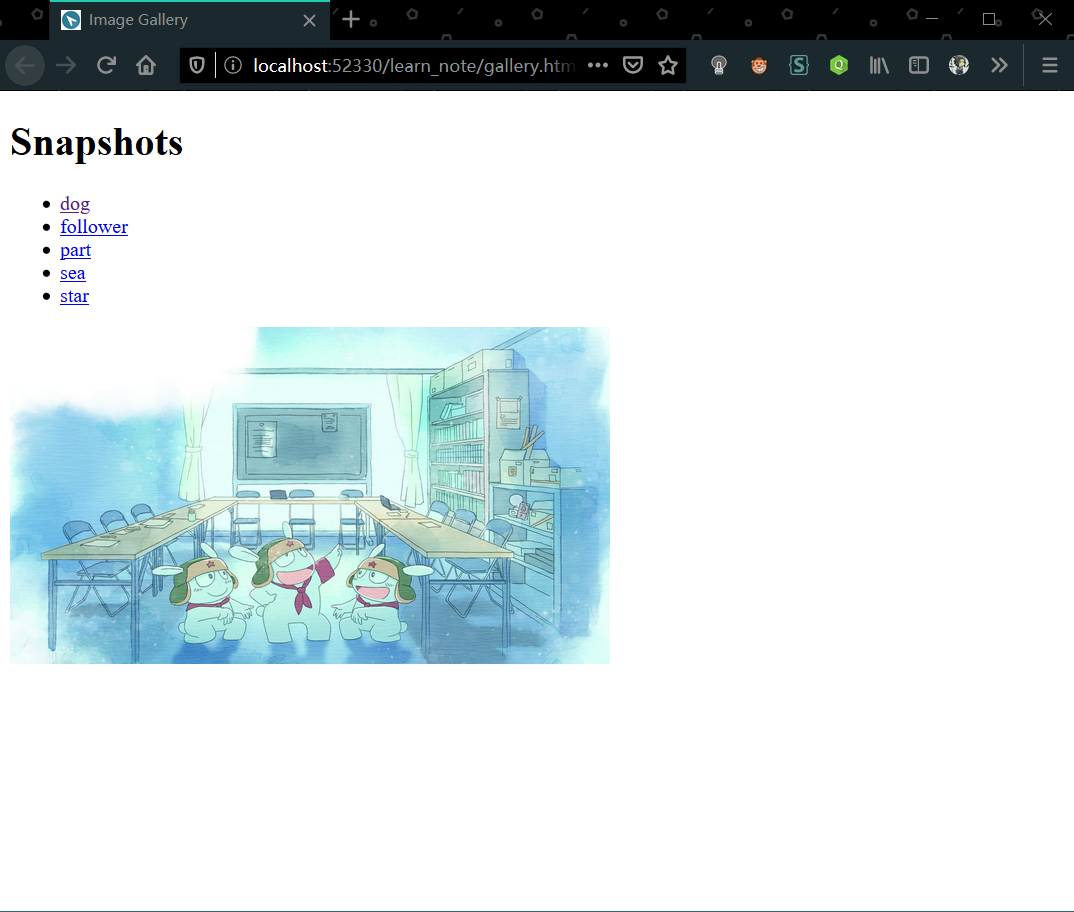
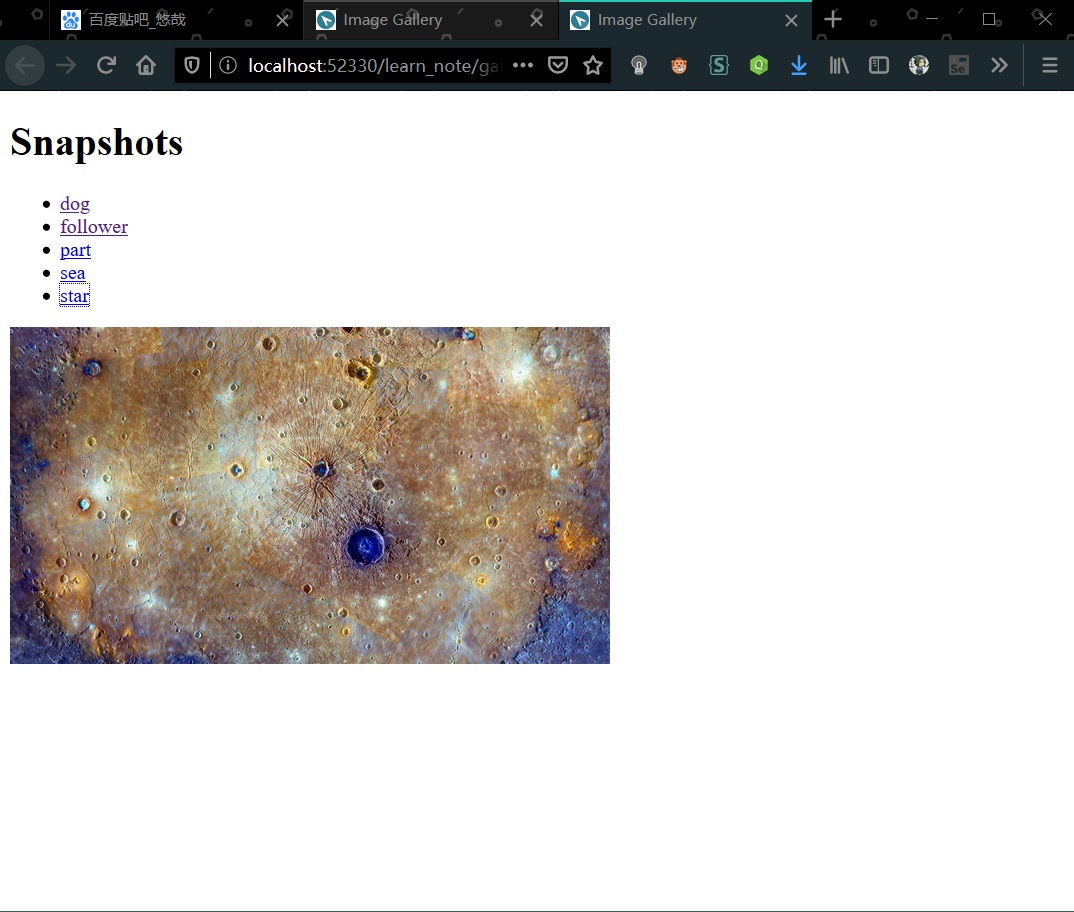
以凉宫系列的第一卷《凉宫春日的忧郁》为例。此处下载下面所需的文件:https://wwa.lanzous.com/b0cqcwbsh 密码:gatu
- 电子书的 txt 文件
- 书自带的插图
- 要制作的书的 pdf 或 epub 文件,方便对照。
- Dobby 软件
蓝奏云链接:https://wwa.lanzous.com/b0cqcw9da 密码:3dfi
github release:https://github.com/jinl1874/e-book/releases/tag/1.0
下载压缩包后,解压到一个英文目录里,打开里面的DobbyGUI.exe即可使用。
创建项目
打开 dooby -> 文件 -> 新建 -> 选择小说模板 -> 填写项目名称 -> 点击确定,然后就会跳转到 dobby 首页。
创建好的项目里面会有一些排版好 xhtml 文件,可以去熟悉一下样式的效果。
排版章节
- 先把除了
copyright.xhml和chapter.xhtml的文件全删掉。 - 双击
chapter.xhml文件,把凉宫的“序曲”文本粘贴上去,然后全选文本,在右边的段落样式里选择“正文宋体”。
- 把光标移动到章节名(这里即序曲)那里,在右边选择标题样式,觉得哪个顺眼就选哪个。
- 检查一下整个章节,如有特殊的文本需要特殊的处理。比如:
- 如果有注释的话,在右边的插件工具里找到多看注释,然后把光标移动要注释的词上,填上注释文本,再点击插入即可,记得把原来的注释文本删去;
- 若有一些信件、电报或者报纸之类的文本,可以选择把段落样式改为引文;
- 如果存在副章节点的话,可以将其放在章节名下一行,段落样式选择“扉章文字偏右”;
- 在后记里可以选择使用“引文楷体”。
- 在左边的“图书浏览器”里右键
chapter.xhtml文件,选择新建空白章节,项目会根据右键的文件名,来自动命名递增数字的文件名。比如这样项目就会创建一个chapter1.xhtml文件,如果是在chapter1.xhtml新建,那么创建的文件名就是chapter2.xhtml。 - 在新建的
chapter1.xhtml文件粘贴上下一章的文本,再根据上面的流程走。 - 直到把所有的章节都排版完成。
记得每做好一个后要(ctrl+s)保存,不然崩溃的时候……
图片
- 添加图片:在左边的图片目录上右键,再点击添加已有文件,把下载好的图片全选上。
- 设置全屏封面:在文本目录上右键 -> 新增全屏插图页 -> 选择图片 -> 确定。
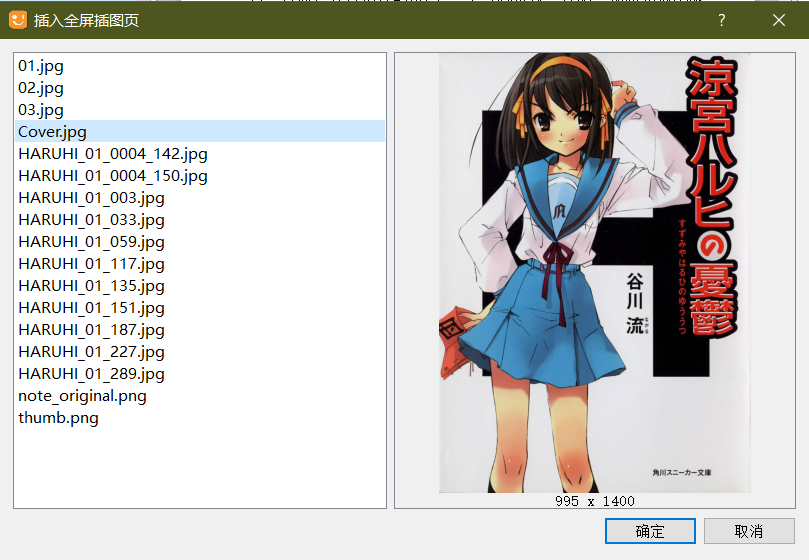
再把这个文件放在顶部位置,并改名cover.xhtml。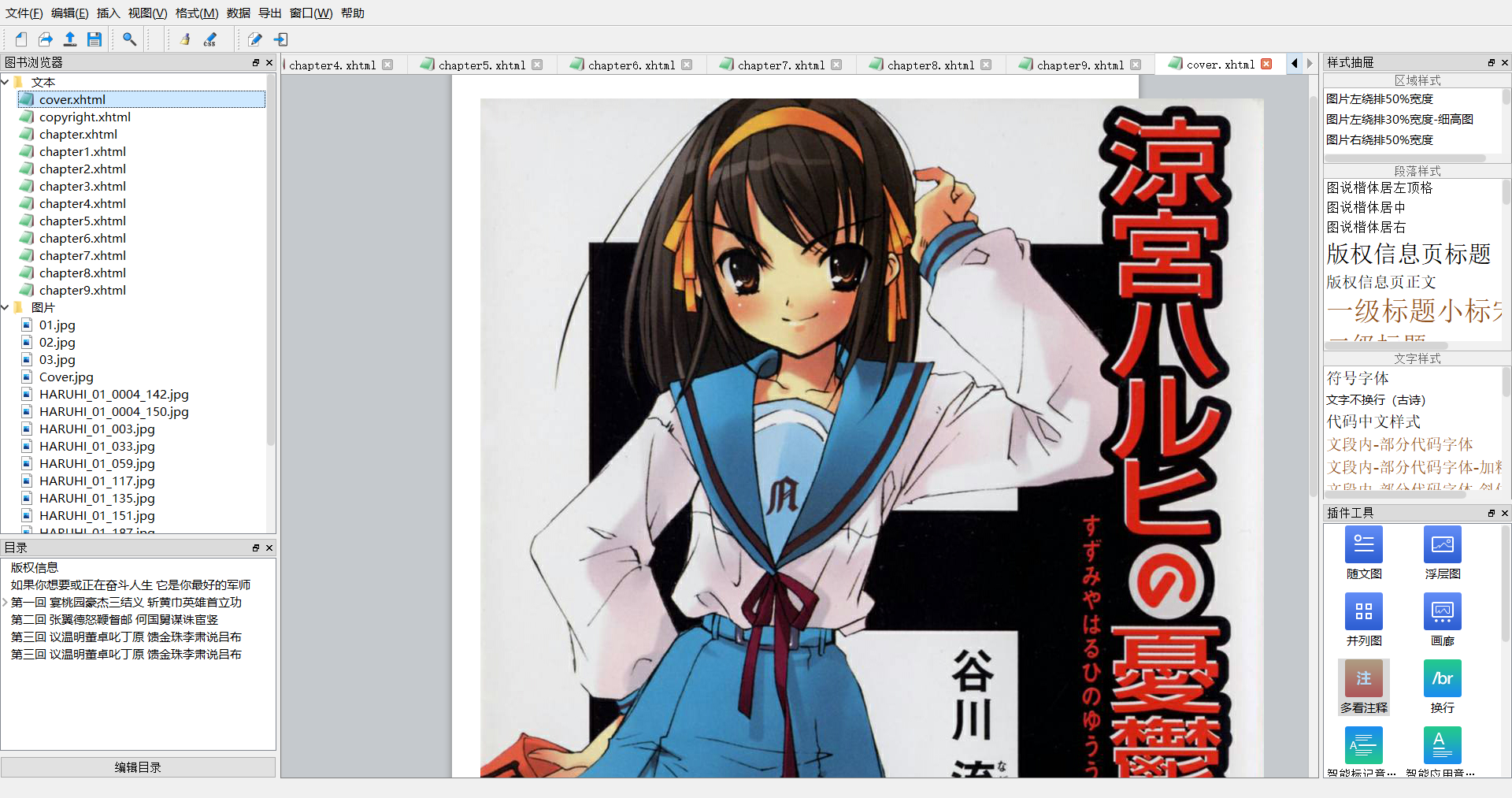
- 彩页:新建一个文件,命名为
inset_0.xhtml,在右边的插件工具里选择浮层图(可以点开查看大图),样式选择“无”。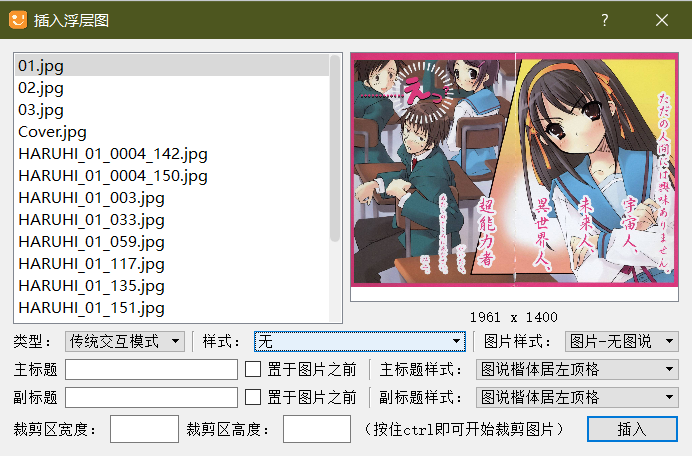
对照着本书的 epub 文件,按照顺序一个个添加,如果添加不了,就再新建一个文件添加。
彩页的位置是在copyright.xhtml文件下面。 - 插图:同样是对照 epub 文件,按“ctrl+F”调出搜索框,然后搜索插附近的文字,找到插图所在的位置。选择“插件工具”的“随文图”,选择图片插入。
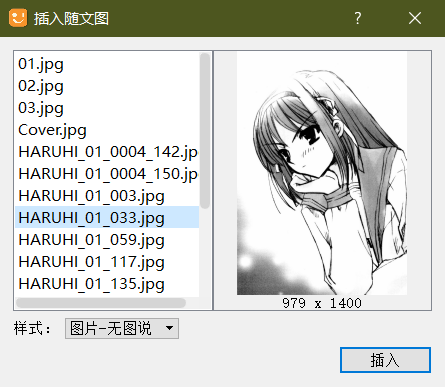
一般来说,一章只有一张插图,不过也有特殊的。相继把所有的插图都插入后,就可以进行下一环节————填写版权信息了。
版权信息
- 在
copyright.xhtml文件写上本书的版权信息,包括但不限于作者、书名、译者、ISBN、校对、制作等信息,如果准备的 epub 文件里有,那就直接照抄;如果没有,最好上豆瓣查找,那里的信息比较全。 - 还可以加上一些免责任声明,比如“仅供个人学习交流,禁止商业用途。下载后请在 24 小时内删除,制作者不负任何责任。转载时,请注明以上信息,尊重翻译者的辛勤劳动。”这一类文本。
- 段落样式选择“版权信息正文”

目录
点击左下角的编辑目录,再选择“从标题生成目录”,一般这样就足够了。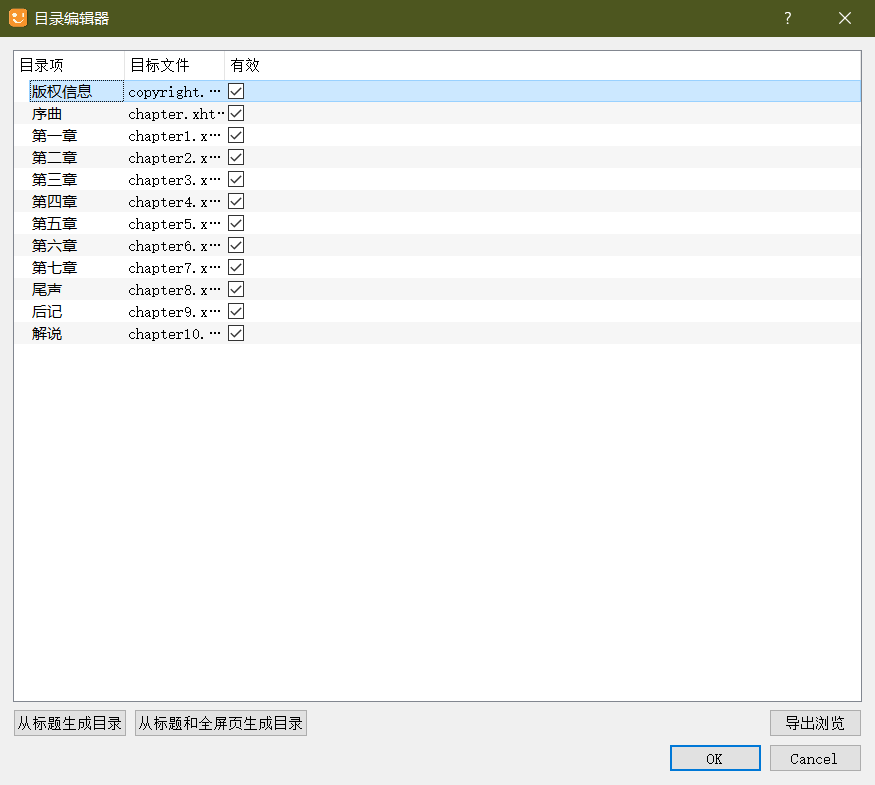
如果有需要添加或者编辑的目录,可以在目录条目那里右键,可选编辑/添加条目。
元数据编辑
- 菜单栏 -> 导出 -> 编辑元数据 -> 填上对应的信息(版权信息有相应的信息)。
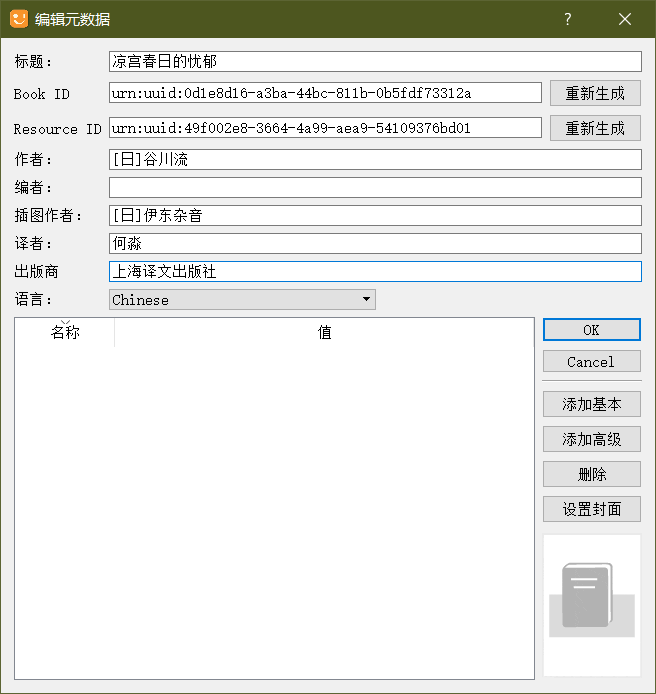
- 添加基本:可以添加 ISBN、出版日期、简介等信息。
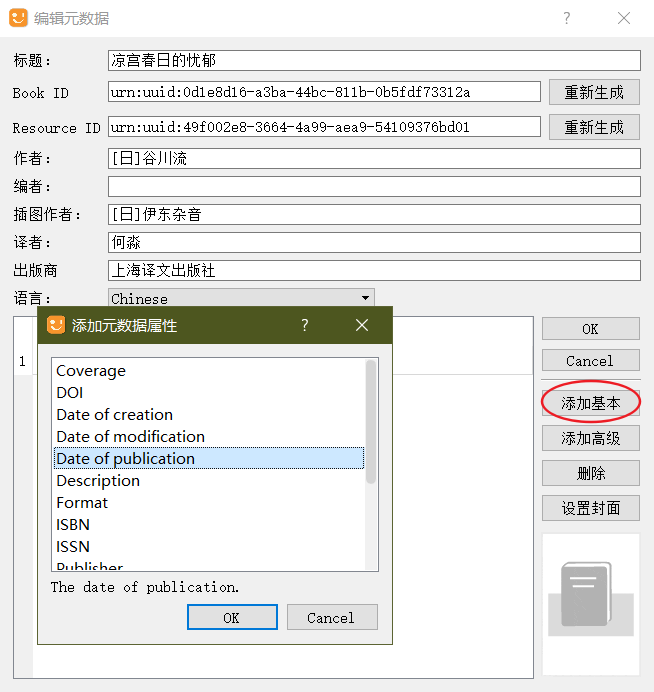
- 设置封面:一般是第一张全屏插画图。
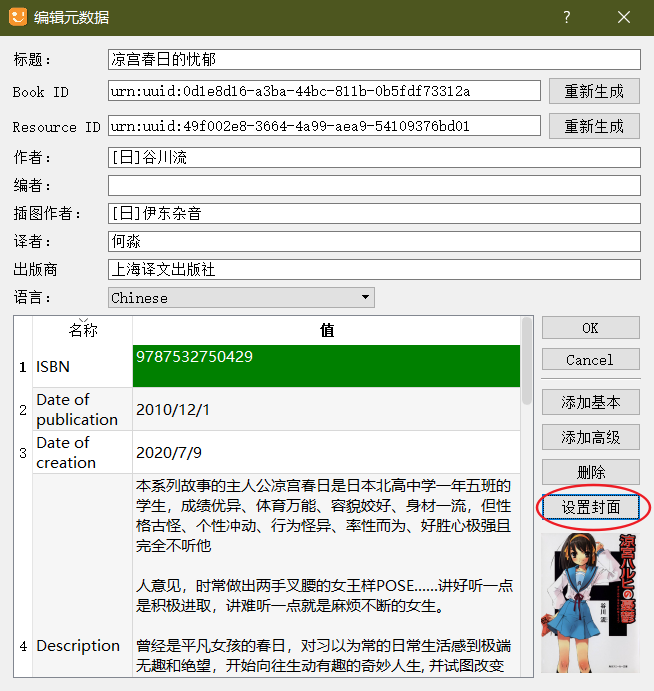
- 完成后点击“OK”。
发布
- 到了这里,就可以发布 epub 电子书了。
- 菜单栏 -> 导出 -> 发布电子书。
阅读器
要想获得最好的阅读体验,推荐下载“多看阅读”。
以上就是制作 epub 电子书的流程,里面还有更多的功能,可以慢慢去挖掘。
欢迎访问个人博客