
详细解析 Python 该如何爬取 bilibili 的视频、弹幕以及封面,最后保存到本地。
环境
用到的 Python 库:
- Python 3.7
- requests
- moviepy
- json
- re
- os
浏览器:Firefox/ 83.0
访问测试
打开一个视频网址,如(https://www.bilibili.com/video/BV1E4411e7ir),然后直接打开发者工具,转到网络,选择XHR文件,再点击播放视频。可以看到很快就传输了很多文件。
可以看出有两种不同的文件,一种是 30280,另一种是 30080。
因为 B 站是把音频和视频分开传输的,所以很明显,一种是视频,另一种就是音频。按大小来分的话,30080 是视频,30280 是音频文件。
首先用试着获取其中的一个文件,来测试一下。
先把请求视频 url 复制下来,再把请求头弄下来,接着发送个请求。
1 | import requests |
然而请求之后发现 flv 文件是空的,再看一下发回的请求文本,显示 403 禁止错误:
1 | <html> |
再仔细观察一下抓包情况,在发送请 get 请求之前,浏览器会发送两个 options 请求,应该是请求许可的意思。分别是请求音频许可和请求视频许可,因为请求 url 与请求音视频的 url 相同。
那么用 session 来发送请求,保存好信息,再去请求链接。修改一下代码:
1 | import requests |
可以看到,test.flv 有文件大小了。
但打开时显示解析错误: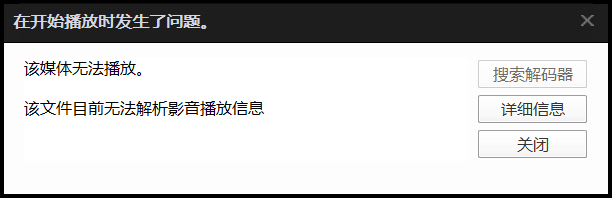
再看一下多个不同请求的请求头,只有 range 发生明显的改变,而且 range 的值里的 bytes 参数,说明这很有可能是一个下载的文件大小范围。那么找到最后一个发送视频请求的的包,把最大值复制下来,然后再设置请求头里的 range 值为 0-最大值,即'Range':'bytes=0-29271958',然后再次运行 py 文件。很明显这次请求回来的文件比之前的大了许多,再点击播放,解析成功,有画面,但是没有声音。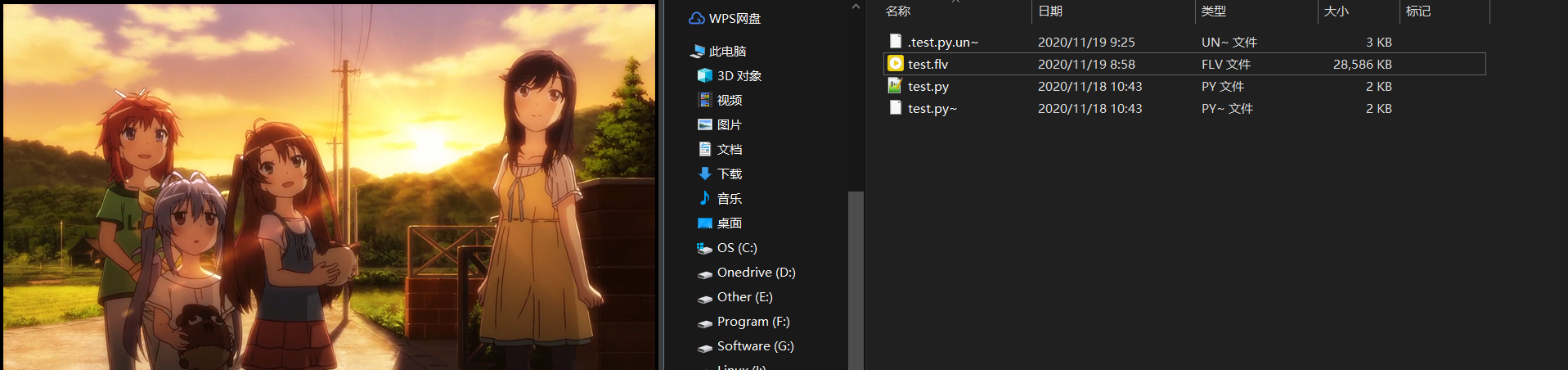
找到 url 地址
要找到请求 url 肯定不能在在抓包里找到,可以尝试看下网页的源代码。
复制一点 url 的信息,在网页中查找,果然找到了信息。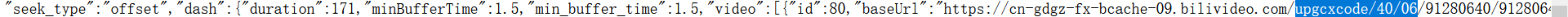
这些信息存在 window.__playinfo__ 里,然后把这个 json 提取出来,放到一个 json 文件里,再用 Firefox 打开。


可以看到,视频的 url 信息就在 ‘video’ 这个键里面,id 指的就是请求的质量,对应着上面的 accept_quality,'id': 116指就是高清 1080p60。
视频的在里面,那么音频的 url 也在 audio这个键里面。
提取也很容易,先把 window._playinfo 用正则表达式获取到,再将其转为 python 的 json 对象,然后就可以取出来了。
请求的 range 参数怎么设置呢?可以把其删去,或者设为'range': 'bytes=0-',这样就会请求一个全文件了。
1 | ## 请求视频页面,注意此时的请求头不是同一个 |
弹幕
要获取 B 站的弹幕,首先得知道 B 站的弹幕文件是从哪加载的。B 站的弹幕文件放在http://comment.bilibili.com/{cid}.xml,所以要获取弹幕,就要获取 B 站的视频的 cid。
视频的 cid 号在页面也可以找到,所以用正则表达式提取。
1 | text = res.text |
封面
封面也可以在页面找到。
1 | text = res.text |
合并音视频
这里使用 python 的 moviepy 库,安装命令pip install moviepy。
导入 from moviepy.editor import *,然后合并导出。
1 | video = VideoFileClip(video_name) |
代码
完整代码查看我的 Github 地址